Introdução
Hoje vamos falar sobre um carinha que é um tanto quanto esquecido quando estamos falando de desenvolvimento de aplicações com C# e .NET.
O escolhido da vez é o Span<T>.
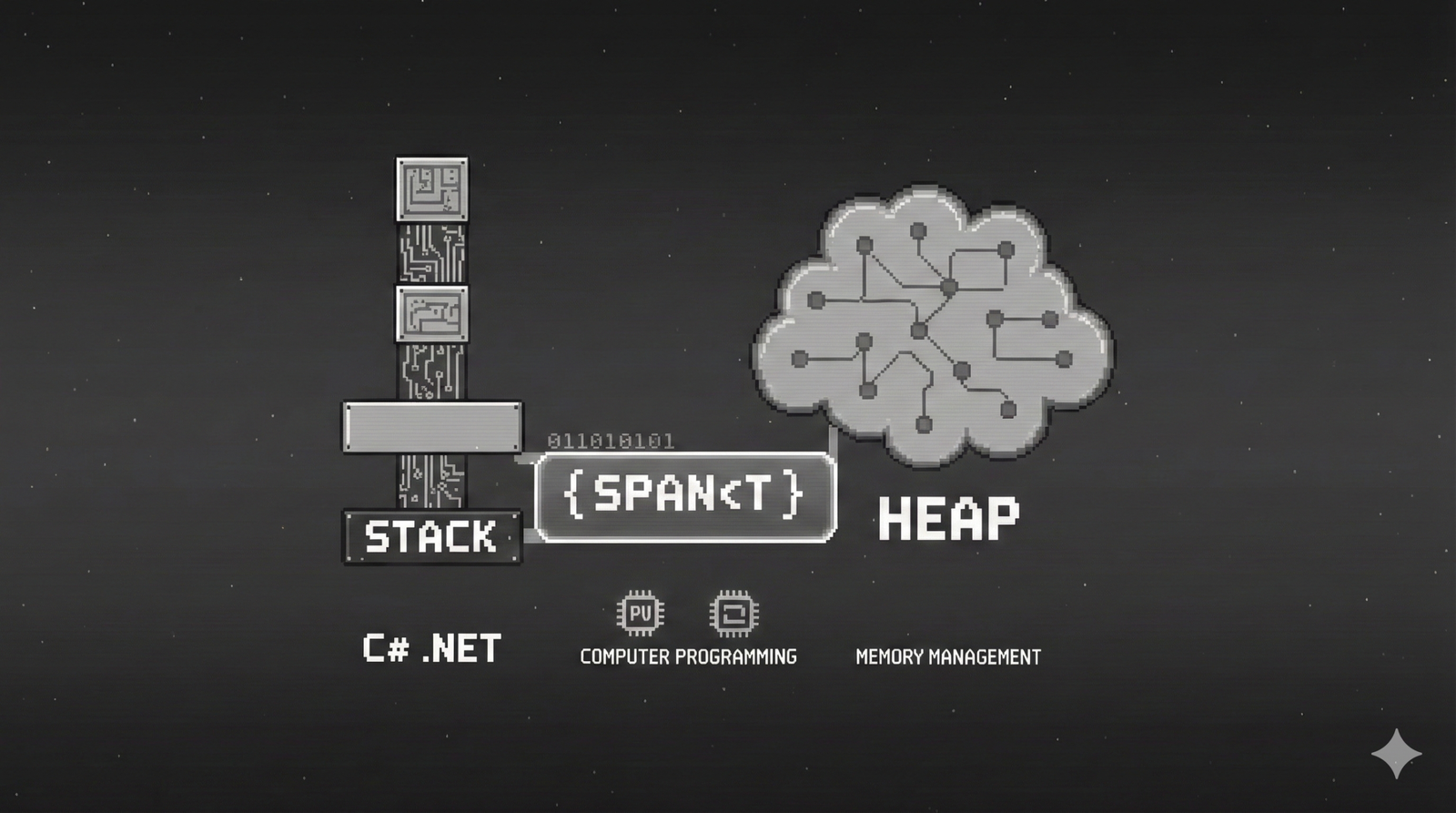
Para facilitar o entendimento deste artigo, seria interessante mas não obrigatório que você esteja familiarizado com os seguintes assuntos: Garbage Collector(GC), Heap Gerenciado, Stack, Generics.
Sem prolongar muito, um Span<T> é um tipo em .NET que permite a representação de uma região contígua de memória arbitrária, podendo elas serem gerenciadas ou não pelo GC ou até mesmo estarem na stack.
Trabalhar com Span<T> possibilita a escrita de código que evita alocações de memória no heap gerenciado mais do que o necessário.
Em aplicações .NET sabemos que na maioria dos casos, quanto menos o GC for acionado mais desempenho teremos na aplicação, isso acontece porque cada vez que o GC é acionado a aplicação pausa por um instante para que ele seja executado e para evitar que o GC seja acionado devemos evitar que objetos sejam alocados na heap gerenciada.
Se aprofundando um pouco mais…
Para entender as vantagens e desvantagens, primeiramente vamos entender como um Span<T> é definido.
public readonly ref struct Span<T>
{
internal readonly ref T _reference;
private readonly int _length;
}
Como podemos ver um Span<T> é uma ref struct, que por definição garante que a sua instância sempre será alocada na Stack e não poderão ser alocadas na heap durante o seu ciclo de vida. Para garantir isso existem uma série de restrições quanto ao seu uso. Essas restrições podem ser encontradas aqui.
Não devemos nos preocupar se estamos alocando ou não um ref struct na heap, o próprio compilador nos ajuda com essas validações na propria IDE, veja alguns exemplos:
public class SpanComoPropriedadeDaClasse
{
public Span<string> Nome { get; set; } // Auto-property cannot be of byref-like type 'System.Span<string>' unless it is an instance member of a 'ref' struct
}
public class TesteSpanMetodosAssincronos
{
public async Task ExecucaoDeTestes(Span<int> span) //Parameters of type 'Span<int>' cannot be declared in async methods
{
return ........
}
}
O fato de um ref struct poder ser armazenado apenas na stack é uma escolha do time do .NET para garantir performance, visto que seria muito custoso para o GC controlar todas as referencias internas dentro de uma struct.
Podemos entender um pouco mais sobre isso aqui.
Criando alguns exemplos
Já entendemos que alocações na heap podem ocasionar perda de performance e que o Span é armazenado na stack, o que nos ajuda a não sobrecarregar o GC. Também sabemos que um Span não cria copia ou novas instâncias e isso pode ser aproveitado em diversos cenários, vejamos alguns exemplos:
int[] numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
var outrosNumeros = numeros[..7];
outrosNumeros[3] = 999;
for (var i = 0; i < numeros.Length; i++)
{
Console.WriteLine($"Elemento no índice {i}: {numeros[i]}");
}
Console.WriteLine();
for (var i = 0; i < outrosNumeros.Length; i++)
{
Console.WriteLine($"Elemento no índice {i}: {outrosNumeros[i]}");
}
A saida para esse codigo:
Elemento no índice 0: 1 Elemento no índice 1: 2 Elemento no índice 2: 3 Elemento no índice 3: 4 Elemento no índice 4: 5 Elemento no índice 5: 6 Elemento no índice 6: 7 Elemento no índice 7: 8 Elemento no índice 8: 9 Elemento no índice 9: 10 Elemento no índice 0: 1 Elemento no índice 1: 2 Elemento no índice 2: 3 Elemento no índice 3: 999 // alterecao realizada apenas na segunda instancia Elemento no índice 4: 5 Elemento no índice 5: 6 Elemento no índice 6: 7
Nesse cenário fica claro que, no momento pegamos uma parte do primeiro array utilizado o operador de range, uma copia desse array foi criada, agora nos temos duas instâncias de array no heap gerenciado, cada um com seus dados sem se relacionar.
Quando fizemos a alteração do índice 3 no segundo array, apenas a segunda instancia sofreu a alteracao.
Com o Span<T> essa segunda alocação não seria realizada, veja o seguinte codigo:
int[] numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
var outrosNumeros = numeros.AsSpan(0, 7);
outrosNumeros[3] = 999;
for (var i = 0; i < numeros.Length; i++)
{
Console.WriteLine($"Elemento no índice {i}: {numeros[i]}");
}
Console.WriteLine();
for (var i = 0; i < outrosNumeros.Length; i++)
{
Console.WriteLine($"Elemento no índice {i}: {outrosNumeros[i]}");
}
A saida para esse codigo:
Elemento no índice 1: 2 Elemento no índice 2: 3 Elemento no índice 3: 999 // alterado no primeiro array Elemento no índice 4: 5 Elemento no índice 5: 6 Elemento no índice 6: 7 Elemento no índice 7: 8 Elemento no índice 8: 9 Elemento no índice 9: 10 Elemento no índice 0: 1 Elemento no índice 1: 2 Elemento no índice 2: 3 Elemento no índice 3: 999 // alterado no segundo array Elemento no índice 4: 5 Elemento no índice 5: 6 Elemento no índice 6: 7
Essa segunda implementação altera os dois arrays porque o Span<T> não cria uma nova instância para o segundo array, ele apenas faz referência ao primeiro item do Array.
Mas e se quiséssemos pegar o array a partir do meio?
Simples, poderíamos utilizar o método de extensão “Slice” ou até mesmo o próprio método “.AsSpan()” passando como parametro qual posicao do array queremos de referencia.
Vejo no exemplo:
int[] numeros = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
//var outrosNumeros = numeros.AsSpan(5, 7); - Porcao do array utilizando o AsSpan.
var outrosNumeros = numeros.AsSpan().Slice(5, 7); // Porcao do array com slice
outrosNumeros[3] = 999;
for (var i = 0; i < numeros.Length; i++)
{
Console.WriteLine($"Elemento no índice {i}: {numeros[i]}");
}
Console.WriteLine();
for (var i = 0; i < outrosNumeros.Length; i++)
{
Console.WriteLine($"Elemento no índice {i}: {outrosNumeros[i]}");
}
Com essa implementação referenciamos agora nao o inicio do Array, e sim a partir de uma posição específica desse array, sem criar copias e novas alocações no heap gerenciado.
Utilizando Span<T> com strings
Podemos utilizar Span<T> para manipular qualquer região contígua de memória, inclusive strings.
A unica diferenca nesse cenario que, quando trabalhamos com string não estamos especificamente utilizando um Span<T>, na realidade por strings serem imutáveis, quando vamos utilizá-lo existe uma conversão implícita que transforma o Span<T> em um ReadOnlySpan<T>.
Como strings são imutáveis, essa é a forma correta para se trabalhar com elas e a equipe da microsoft criou isso para nos.
Em termos mais técnicos, a diferenca principal esta no metodo que retorna uma referencia para o indice selecionado.
Enquanto o Span<T> retorna uma referência sem restrições de escrita:
public ref T this[int index]
{
[Intrinsic, NonVersionable, MethodImpl(MethodImplOptions.AggressiveInlining)] get
{
if ((uint) index >= (uint) this._length)
ThrowHelper.ThrowIndexOutOfRangeException();
return ref Unsafe.Add<T>(this._reference, (IntPtr) (uint) index);
}
}
O ReadOnlySpan<T> retorna uma referência com a restrição de apenas leitura:
public readonly ref readonly T this[int index]
{
[Intrinsic, NonVersionable, MethodImpl(MethodImplOptions.AggressiveInlining)] get
{
if ((uint) index >= (uint) this._length)
ThrowHelper.ThrowIndexOutOfRangeException();
return ref Unsafe.Add<T>(this._reference, (IntPtr) (uint) index);
}
}
E sabe o que é mais interessante disso tudo? Ver que funcionalidades que foram implementada ao longo dos anos com as evoluções do .NET habilitaram de forma majestosa a implementação do Span<T> e ReadOnlySpan<T> de uma forma muito elegante.
Bom, depois dessa explicação vamos para nosso exemplo com strings.
Olhando a documentação da microsoft me deparei com alguns exemplos de manipulação de strings que me pareciam um tanto quanto ineficientes em termos que alocacao de memoria (Como se eu tivesse alguma autoridade para julgar os códigos da microsoft).
O primeiro deles realizava a busca de um termo em uma string, ou seja, um cenario bem factivel para os problemas que temos no dia a dia.
Muitas vezes processando arquivos/textos precisamos fazer esse tipo de busca para extrair ou verificar se determinado termo existe na string desejada.
Segue a implementação que encontrei nessa documentação da microsoft.
string text = """
Historically, the world of data and the world of objects
have not been well integrated. Programmers work in C# or Visual Basic
and also in SQL or XQuery. On the one side are concepts such as classes,
objects, fields, inheritance, and .NET APIs. On the other side
are tables, columns, rows, nodes, and separate languages for dealing with
them. Data types often require translation between the two worlds; there are
different standard functions. Because the object world has no notion of query, a
query can only be represented as a string without compile-time type checking or
IntelliSense support in the IDE. Transferring data from SQL tables or XML trees to
objects in memory is often tedious and error-prone.
""";
string searchTerm = "data";
//Convert the string into an array of words
char[] separators = ['.', '?', '!', ' ', ';', ':', ','];
string[] source = text.Split(separators, StringSplitOptions.RemoveEmptyEntries);
// Create the query. Use the InvariantCultureIgnoreCase comparison to match "data" and "Data"
var matchQuery = from word in source
where word.Equals(searchTerm, StringComparison.InvariantCultureIgnoreCase)
select word;
// Count the matches, which executes the query.
int wordCount = matchQuery.Count();
Console.WriteLine($"""{wordCount} occurrences(s) of the search term "{searchTerm}" were found.""");
/* Output:
3 occurrences(s) of the search term "data" were found.
*/
Basicamente esse algoritmo acima busca o termo “data” na string em questão, sem levar em consideração letras maiúsculas ou minúsculas.
Como sabemos bem strings são imutáveis, e a utilizacao do metodo “.Split()” faz com que seja alocada uma nova string para cada tipo de separador que utilizamos na operacao.
E cada string nova gerada, está sendo armazenada no heap gerenciado e salvo a referência para essa string em cada posição do array.
Alem disso, temos algumas outras operações com LINQ logo abaixo que também podem criar alocações.
Proposta de solução com ReadOnlySpan<T>
Feitas as devidas alterações para podermos comparar as implementações, fiz uma nova versão deste código utilizando ReadOnlySpan<T>.
using BenchmarkDotNet.Attributes;
namespace ExemplosMs;
[MemoryDiagnoser]
public class ExemploMs
{
private string _text;
[GlobalSetup]
public void Setup()
{
_text = """
Historically, the world of data and the world of objects have not been well integrated.
Programmers work in C# or Visual Basic
and also in SQL or XQuery. On the one side are concepts such as classes,
objects, fields, inheritance, and .NET APIs. On the other side
are tables, columns, rows, nodes, and separate languages for dealing with
them. Data types often require translation between the two worlds; there are
different standard functions. Because the object world has no notion of query, a
query can only be represented as a string without compile-time type checking or
IntelliSense support in the IDE. Transferring data from SQL tables or XML trees to
objects in memory is often tedious and error-prone.
""";
}
[Benchmark]
public int Execute()
{
var searchTerm = "data";
//Convert the string into an array of words
char[] separators = ['.', '?', '!', ' ', ';', ':', ','];
var source = _text.Split(separators, StringSplitOptions.RemoveEmptyEntries);
// Create the query. Use the InvariantCultureIgnoreCase comparison to match "data" and "Data"
var matchQuery = from word in source
where word.Equals(searchTerm, StringComparison.InvariantCultureIgnoreCase)
select word;
// Count the matches, which executes the query.
return matchQuery.Count();
}
[Benchmark]
public int ExecuteOtimizado()
{
var searchTerm = "data".AsSpan();
var textAsSpan = _text.AsSpan();
var nameCount = 0;
for (var x = 0; x < textAsSpan.Length; x++)
{
if (textAsSpan[x] != searchTerm[0] && (textAsSpan[x] + 32) != searchTerm[0])
continue;
if (textAsSpan[x..].Length < searchTerm.Length)
return 0;
if (textAsSpan.Slice(x, 4).Equals(searchTerm, StringComparison.InvariantCultureIgnoreCase))
{
nameCount++;
}
}
return nameCount;
}
}
Estou utilizando a biblioteca BenchmarkDotNet para nos ajudar a entender como os dois codigos estao trabalhando com alocações na heap gerenciada.
Segue o resultado:
| Method | Mean | Error | StdDev | Gen0 | Allocated | |----------------- |---------:|----------:|----------:|-------:|----------:| | Execute | 5.224 us | 0.0083 us | 0.0069 us | 0.1221 | 6440 B | | ExecuteOtimizado | 1.040 us | 0.0047 us | 0.0044 us | - | - |
Como podemos ver a primeira implementação alocou cerca de 6440B, enquanto a segunda solução não teve nenhuma alocação no heap gerenciado.
O ponto principal aqui é, não alocamos na heap mais do que o necessário para buscar as informações nessa string.
Enquanto metodos como “.Split()” criam copias da string, trabalhando com ReadOnlySpan<T> não se cria copia alguma, apenas cria uma referencia para uma string que ja existe na heap.
Trazendo um outro exemplo de implementação com arquivos
using BenchmarkDotNet.Attributes;
namespace ExemplosMs;
[MemoryDiagnoser]
public class TerceiroExemplo
{
[Benchmark]
public void Execute()
{
string[] names = File.ReadAllLines("names.csv");
string[] scores = File.ReadAllLines("scores.csv");
IEnumerable<Student> queryNamesScores = from nameLine in names
let splitName = nameLine.Split(',')
from scoreLine in scores
let splitScoreLine = scoreLine.Split(',')
where Convert.ToInt32(splitName[2]) == Convert.ToInt32(splitScoreLine[0])
select new Student
(
FirstName: splitName[0],
LastName: splitName[1],
ID: Convert.ToInt32(splitName[2]),
ExamScores: (from scoreAsText in splitScoreLine.Skip(1)
select Convert.ToInt32(scoreAsText)
).ToArray()
);
// Optional. Store the newly created student objects in memory
// for faster access in future queries. This could be useful with
// very large data files.
List<Student> students = queryNamesScores.ToList();
// Display each student's name and exam score average.
foreach (var student in students)
{
Console.WriteLine(
$"The average score of {student.FirstName} {student.LastName} is {student.ExamScores.Average()}.");
}
/* Output:
The average score of Omelchenko Svetlana is 82.5. The average score of O'Donnell Claire is 72.25. The average score of Mortensen Sven is 84.5. The average score of Garcia Cesar is 88.25. The average score of Garcia Debra is 67. The average score of Fakhouri Fadi is 92.25. The average score of Feng Hanying is 88. The average score of Garcia Hugo is 85.75. The average score of Tucker Lance is 81.75. The average score of Adams Terry is 85.25. The average score of Zabokritski Eugene is 83. The average score of Tucker Michael is 92. */ }
[Benchmark]
public async Task ExecuteOtimizado()
{
IEnumerable<Student> students = [];
var scorePorAlunoDic = new Dictionary<int, int[]>();
await foreach (var scoreLine in File.ReadLinesAsync("scores.csv"))
{
var indexVirgulaScoreId = scoreLine.AsSpan().IndexOf(',');
var scoreIdSpan = int.Parse(scoreLine.AsSpan(0, indexVirgulaScoreId));
var stringScoreFormatada = scoreLine.AsSpan(indexVirgulaScoreId + 1);
var scores = new int[4];
var index = 0;
while (true)
{
var nextCommaIndex = stringScoreFormatada.IndexOf(',');
if (nextCommaIndex == -1)
{
scores[index] = int.Parse(stringScoreFormatada);
break;
}
scores[index] = int.Parse(stringScoreFormatada.Slice(0, nextCommaIndex));
stringScoreFormatada = stringScoreFormatada.Slice(nextCommaIndex + 1);
index++;
}
scorePorAlunoDic[scoreIdSpan] = scores;
}
foreach (var line in File.ReadLines("names.csv"))
{
var indexVirgulaId = line.AsSpan().LastIndexOf(',');
var idSpan = int.Parse(line.AsSpan(indexVirgulaId + 1));
var firstNameSpan = line.AsSpan().Slice(0, line.AsSpan().IndexOf(','));
var lastNameSpan = line.AsSpan().Slice(line.AsSpan().IndexOf(',') + 1,
line.AsSpan().LastIndexOf(',') - line.AsSpan().IndexOf(',') - 1);
var id = idSpan;
var student = new Student(
FirstName: firstNameSpan.ToString(),
LastName: lastNameSpan.ToString(),
ID: id,
ExamScores: scorePorAlunoDic[id]
);
students = students.Append(student);
}
foreach (var student in students)
{
Console.WriteLine(
$"The average score of {student.FirstName} {student.LastName} is {student.ExamScores.Average()}.");
}
}
}
public record struct Student(string FirstName, string LastName, int ID, int[] ExamScores);
Para voces terem como referencia, os arquivos seguem a seguinte extrutura:
names.csv Silva,Lucas,1 Santos,Mateus,2 Oliveira,Gabriel,3 Souza,Ana,4 Pereira,Julia,5 scores.csv 1, 54, 97, 44, 62 2, 77, 38, 91, 65 3, 99, 41, 56, 92 4, 60, 85, 78, 97 5, 88, 67, 90, 53
Adicionei cerca de 1000 linhas em cada arquivo, simulando os nomes do usuários com suas respectivas notas.
Sem enrolacao, o resultado do código acima comparando as duas versões é:
| Method | Mean | Error | StdDev |----------------- |---------:|---------:|---------: | Execute | 98.24 ms | 0.687 ms | 0.573 ms | ExecuteOtimizado | 17.02 ms | 1.384 ms | 4.082 ms | Gen0 | Gen1 | Gen2 | Allocated | |----------:|----------:|---------:|-------------:| | 5600.0000 | 1000.0000 | 400.0000 | 281862.54 KB | | - | - | - | 720.79 KB |
Claro que o código acima tem alguns outros problemas além de não utilizar span<T>, como por exemplo alocar todo o arquivo em memoria.
Mas acredito que para fins de comparação os exemplos que vimos acima nos dá uma ótima noção de como span<T> pode nos ajudar a otimizar nossas aplicações e a utilizar a memória de maneira consciente.
Conclusao
Utilizar span<T> ou o ReadOnlySpan<T> pode nos ajudar a melhorar a performance de nossas aplicações, principalmente se tratando de gerenciamento de memoria.
Mas ainda devemos ser criticos com o codigo que escrevemos, devemos sempre estar atentos às boas práticas, devemos estar cientes sobre a forma como alocamos memória em nossas aplicações.
Claro que nem sempre será possível utilizar essa estrutura, em alguns cenarios nao queremos reutilizar a mesma instancia, queremos de forma explicita instancias separadas e unicas. Nesse cenario, o uso de Span<T> ou ReadOnlySpan<T> talvez não seja bem vindo.
O uso dessa estrutura também pode causar algum desconforto para pessoas que não entendem como ela funciona, esse cenario entendo que podemos ajudar, seria essa uma ótima oportunidade de ensinar para alguém algo novo.
Existem muitas outras aplicações com Span<T> e inclusive com o seu parceiro Memory<T>, pretendo trazer mais exemplos e conceitos que podemos nos beneficiar no desenvolvimento de aplicações com C# E .NET.
Referencias
https://learn.microsoft.com/pt-br/dotnet/standard/memory-and-spans
https://learn.microsoft.com/pt-br/dotnet/fundamentals/runtime-libraries/system-span%7Bt%7D
https://learn.microsoft.com/pt-br/dotnet/standard/memory-and-spans/memory-t-usage-guidelines?source=recommendations
https://www.youtube.com/watch?v=5KdICNWOfEQ